
Comment résorber sa dette technique : anticiper ce qui ne se voit pas encore (partie 3)

Arrivé ici, vous avez une application qui tourne bien, avec de bons outils et une bonne vision, en phase avec votre séniorité. Ce troisième volet clôt la série. Si vous débarquez directement, le précédent volet sur la dette profonde et structurante est à lire en amont pour bien suivre le fil.
La dette cachée, c’est quoi ?
Il y a toujours une dette cachée, même quand tout semble parfait. Elle se loge dans des endroits qu’on ne remarque pas tout de suite : des dépendances implicites, des modules sous-testés, ou des hypothèses obsolètes. Elle ne se manifeste pas par des bugs ou des crashs. Elle attend son heure.
Comment on la débusque ?
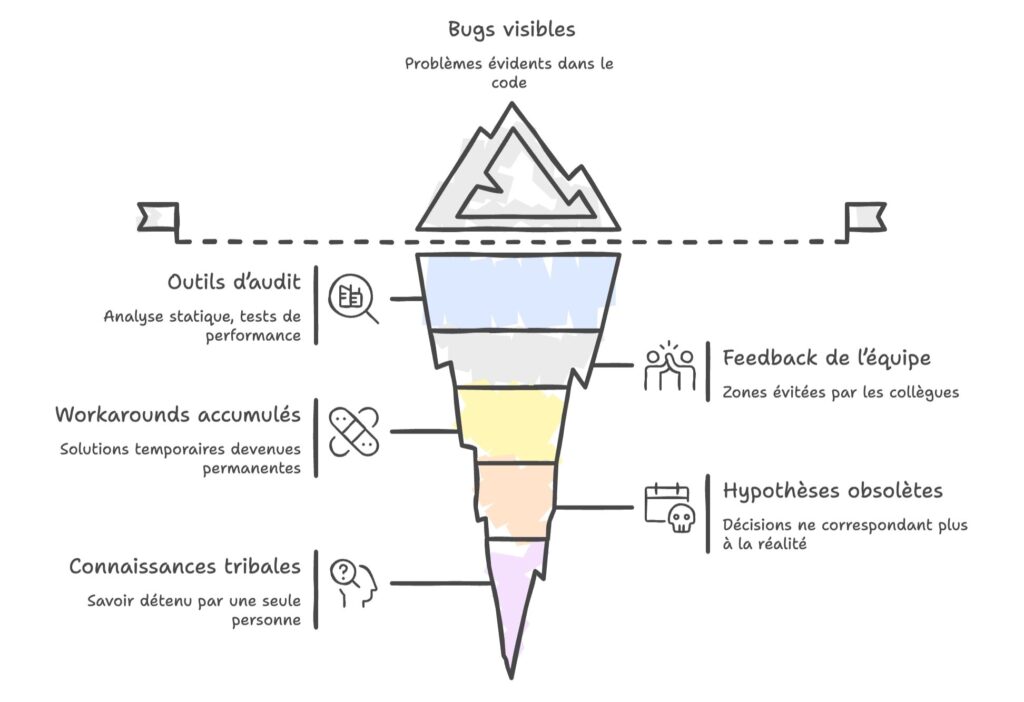
Pour mettre en lumière la dette cachée, il faut s’appuyer sur une compréhension totale du projet. C’est souvent un travail d’enquête, car cette dette ne se manifeste pas de façon évidente. Voici les leviers qui nous ont permis de la débusquer :
- Outils d’audit avancés : l’analyse statique, les tests de performance ou les scanners de sécurité peuvent révéler des zones problématiques que vous n’aviez pas identifiées. Dans cette phase, vous avez le recul pour interpréter ces résultats correctement.
- Feedback de l’équipe : vos collègues connaissent souvent des zones qu’ils évitent de toucher. « On ne touche pas à ça, c’est fragile. » Ces zones sont de la dette cachée. Prenez le temps de les lister.
- Les workarounds accumulés : ces petits hacks mis en place « en attendant » qui sont toujours là. Ces conditions spéciales pour gérer des cas edge. À force, ils forment une couche de complexité invisible.
- Les hypothèses obsolètes : des décisions prises il y a 2 ans qui ne correspondent plus à la réalité. L’API qui devait évoluer mais qui est restée figée. Le volume de données qui a explosé alors que l’archi était prévue pour moins.
- Les connaissances tribales : ce que seule une personne de l’équipe sait. « Demande à Pierre, c’est lui qui connaît cette partie. » Si Pierre part, cette connaissance part avec lui. C’est une dette, même si elle n’est pas dans le code.
Les outils de cette phase
À ce stade, les outils servent moins à découvrir qu’à piloter, communiquer et optimiser. Voici ceux qu’on a mobilisés :
| Outil | But / Mission |
|---|---|
| Rituels | S’organiser autour des différents outils mis en place pour suivre de façon régulière les remontées. |
| Heatmaps fonctionnelles | Visualiser les zones critiques de l’application et leur état (vert, jaune, rouge). |
| Grafana × OpenTelemetry | Donner de l’autonomie aux autres équipes pour comprendre un bug. Connecté aux logs backend avec Grafana Tempo, on voit toute la chaîne d’enchaînement des services avec des infos complémentaires (OS, version de l’app, etc.). |
| Firebase Performance | Visualiser la performance de l’application. Suivre les calls réseaux et autres metrics pour identifier les optimisations possibles. |
| Outil de détection du code inutilisé | Nettoyer le code inutilisé pour ne pas garder les choses qui ne servent pas. Tout reste dans Git, rien n’est perdu. |
| Firebase Remote Config | Gérer l’activation ou la désactivation d’un bout de code. Permet de faire des migrations progressives en production. |
Les rituels : structurer le suivi
De notre côté, on a mis en place des remontées périodiques et des points réguliers pour faire le bilan sur chaque outil, voir comment il évolue, et s’affecter des tâches.
Essayez de répartir dans le temps ces points pour les outils. Si vous organisez une grosse réunion avec les remontées de tous vos outils de suivi, ça peut devenir très frustrant face à l’ampleur de la charge de travail. Il vaut mieux évaluer la charge que cela génère et adapter avec votre équipe. Trouvez un juste milieu. Avec la montée en compétence de chacun, vous verrez évoluer votre façon de corriger les problèmes.
Un conseil : si vous avez de l’expérience, prenez sur vous la charge de réduire le niveau des remontées. Par exemple, n’afficher que les remontées critiques tant qu’il y en a, puis ouvrir progressivement. Cela permet de se concentrer sur les priorités plus rapidement.
Les Heat Maps fonctionnelles : communiquer sur la dette
On a eu des problématiques de communication avec l’équipe produit au fur et à mesure que notre dette technique diminuait. De l’extérieur, tout semblait bien se passer : l’application fonctionnait bien, peu de crashs, peu d’erreurs, un aspect visuel correct. Mais on avait toujours en tête des parties qu’il fallait revoir pour éviter que l’application ne tombe du jour au lendemain.
Pour cela, on a analysé feature par feature l’application (d’abord de façon macro, puis avec plus de précision au fil du temps) pour évaluer l’état de chacune. On a tout mis à plat dans un document, et pour rendre cela visuel, on a créé une sorte de Heat Map à la main, avec un code couleur simple :
- Vert : la feature est saine, elle fonctionne correctement
- Orange : la feature nécessite une attention particulière, à surveiller
- Rouge : la feature est difficile à faire évoluer, elle freine le développement business
- Noir : zone morte, la feature nécessite une refonte complète
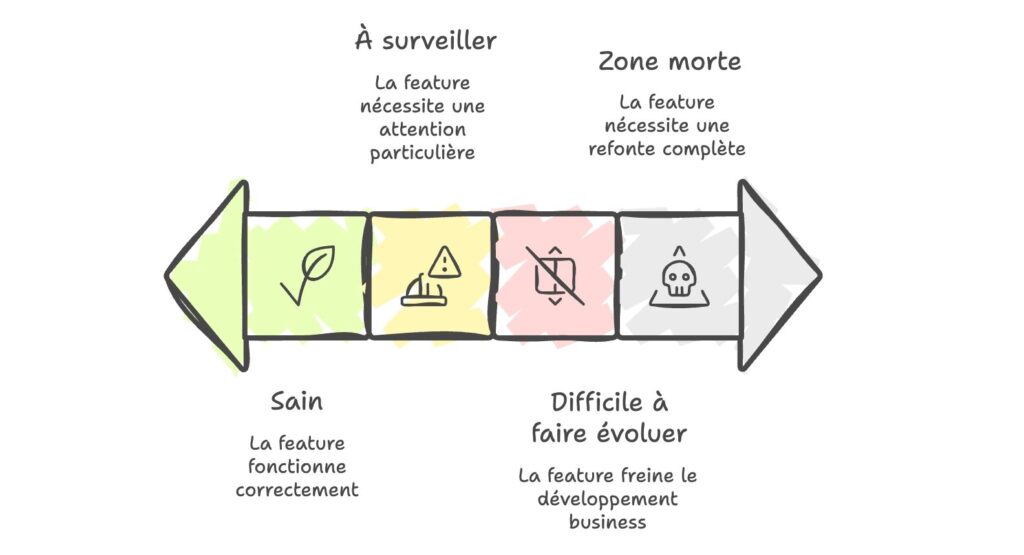
Grâce à cette Heat Map, on a pu montrer factuellement l’état de l’application. Pas mal de parties étaient OK, mais certaines étaient complexes à maintenir. Cela a permis aux différentes équipes de prendre en main leur périmètre et de voir, côté produit, comment intégrer ces travaux dans la roadmap. L’idée était aussi de formaliser sur un document ce qu’on avait en tête.
Des librairies dépréciées laissées de côté car trop structurantes
On a renforcé la communication et fait des présentations pour expliquer ce que cela impliquait, tout en rassurant l’entreprise sur notre capacité à gérer un sujet aussi structurant. On a aussi utilisé la Heat Map pour visualiser cette partie, même si c’est quelque chose de plus technique.
Notre plus gros enjeu structurant depuis un an est de préparer la transition de notre navigation côté Android, qui repose sur une librairie dépréciée utilisant les FragmentManager.
Optimiser les performances : Firebase Performance et Grafana
C’est dans cette phase que l’optimisation des performances prend tout son sens. Avant, on mettait en place des outils pour observer. Maintenant, on a assez de recul et de données pour agir.
Avec Firebase Performance, on a pu analyser l’utilisation des requêtes webservices et identifier les appels réseau à optimiser. On ne l’a pas fait tout de suite. On a d’abord mis l’outil en place de façon légère, observé les données, compris les patterns. Et quand on a eu une vision claire des problèmes, on a pu prioriser les optimisations qui avaient vraiment un impact.
Grafana couplé à OpenTelemetry nous a permis d’aller encore plus loin. On voit maintenant toute la chaîne d’exécution d’une requête : du mobile jusqu’au backend, en passant par tous les services intermédiaires. Quand un utilisateur remonte un problème de lenteur, on peut tracer exactement ce qui s’est passé. Ça donne aussi de l’autonomie aux autres équipes : elles peuvent investiguer sans forcément solliciter les devs mobile.
L’idée, c’est que les outils de performance deviennent vraiment utiles quand vous maîtrisez votre application. Avant ça, vous risquez de vous noyer dans des métriques sans savoir quoi en faire.
Firebase Remote Config : migrer en douceur
Quand vous devez remplacer un composant structurant de votre application, vous ne pouvez pas tout basculer d’un coup. C’est là que Firebase Remote Config devient précieux.
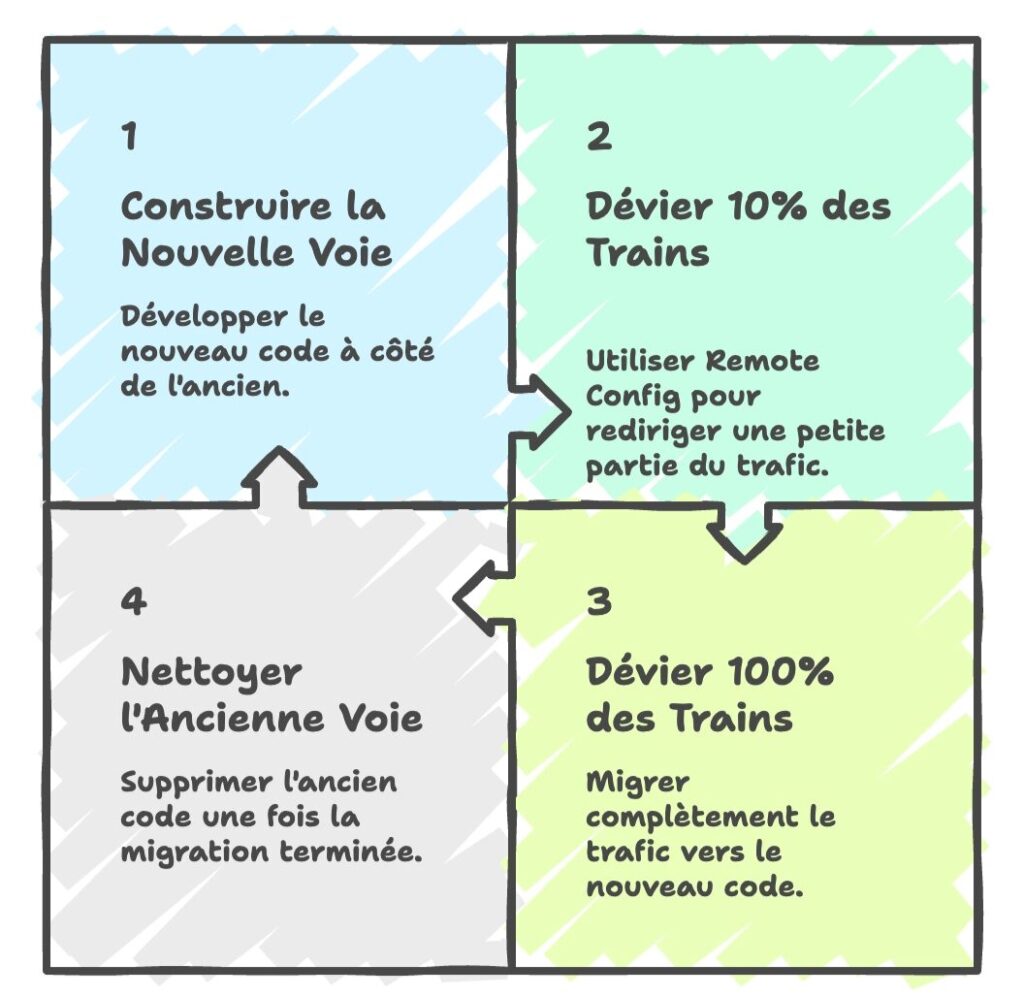
L’idée est simple : vous gardez l’ancien code et le nouveau côte à côte, et vous contrôlez lequel est actif via un flag distant. Ça vous permet de :
- Tester en conditions réelles : activer la nouvelle implémentation pour un petit pourcentage d’utilisateurs et observer le comportement.
- Rollback instantané : si quelque chose ne va pas, vous désactivez le flag sans avoir à redéployer.
- Migration progressive : vous augmentez progressivement le pourcentage d’utilisateurs sur la nouvelle version jusqu’à 100 %.
De notre côté, on l’a utilisé pour plusieurs migrations, business comme techniques. Côté technique, deux cas majeurs :
- Le changement complet de notre backend : on a maintenu les deux backends en parallèle pendant la transition, et le switch en production s’est fait de façon transparente pour les utilisateurs. C’était un chantier énorme, mais Remote Config nous a permis de maîtriser les impacts à chaque étape.
- La migration de notre feature de chat : on a fait cohabiter l’ancienne et la nouvelle implémentation. Le switch en production s’est fait progressivement. Aucune coupure, aucun stress.
Ça rassure tout le monde : l’équipe technique, le produit, et les parties prenantes. On avance sereinement sur des sujets qui auraient pu être très risqués. Une fois la migration terminée et validée, on supprime l’ancien code et le flag. C’est important de ne pas laisser traîner ces feature flags indéfiniment, sinon vous créez une nouvelle forme de dette.
Nouveautés des plateformes
Les nouveautés comme Compose ou SwiftUI sont intéressantes à mettre en place pour l’avenir de l’application et des personnes qui vont travailler dessus.
Comment en parler sans tout casser ?
Une fois la dette détectée, il faut la communiquer. Et pour ça, pas question de parler en jargon incompréhensible aux non-développeurs :
- Adaptez votre discours : parlez des conséquences réelles de la dette (retards, instabilité), pas de détails techniques abscons.
- Proposez des solutions progressives : on ne la résout pas tout d’un coup. Il s’agit de la réduire petit à petit, tout en gardant les objectifs business en tête.
Conclusion
La dette technique n’est jamais totalement éliminée. L’important, c’est de l’intégrer dans la routine de l’équipe : des revues de code régulières, des audits périodiques, et surtout une culture de responsabilité partagée.
Cette série a parcouru trois étapes : la découverte de la dette de surface, la compréhension de la dette profonde structurante, puis la mise en lumière de la dette cachée. Pas de solution miracle : la gestion de la dette technique reste du cas par cas, selon votre équipe, votre contexte et vos contraintes. Avec des efforts structurés, de la communication et du pragmatisme, on réduit son impact et on rend le travail plus agréable.
Merci d’avoir suivi ces trois volets. J’espère que ce partage d’expérience vous aidera à aborder vos propres chantiers avec plus de sérénité et de clarté.
À retenir
Cette phase finale est celle où vous passez de la gestion technique pure à une vraie collaboration avec les autres équipes. La capacité à visualiser et communiquer l’état de la dette technique devient aussi importante que la capacité à la corriger.
Résumer cet article avec :


