
Comment résorber sa dette technique : poser le diagnostic (partie 1)

La découverte d’un projet est toujours une phase délicate. On tombe sur des problèmes qu’on ne comprend pas encore, on ne maîtrise rien, et ça fait peur. Pour les développeurs, la dette technique, c’est cet emprunt rapide qu’on contracte pour livrer un MVP ou tenir une deadline. Mais comme tout emprunt, elle vient avec des intérêts : du code difficile à maintenir, une architecture qui s’essouffle, des décisions qu’on regrette dans le calme après la tempête.
Cet article ouvre une série en trois volets sur la dette technique. On démarre par la dette de surface, avant de plonger dans la dette profonde (partie 2), puis de mettre en lumière la dette cachée (partie 3).
Un disclaimer avant de commencer : chaque équipe est différente. Ne prenez pas ce qu’on a fait pour l’appliquer tel quel chez vous. L’important, c’est de comprendre les concepts derrière : la gestion de la charge mentale, la priorisation, l’adaptation au contexte.
C’est quoi, la dette de surface ?
C’est le genre de dette technique qui saute aux yeux quand on commence un nouveau projet ou qu’on intègre un legacy. Vous voyez le tableau : des fonctions spaghetti de 500 lignes, une doc désuète ou manquante, des tests unitaires inexistants. Bref, c’est la poussière qu’on pousse sous le tapis pour shipper plus vite.
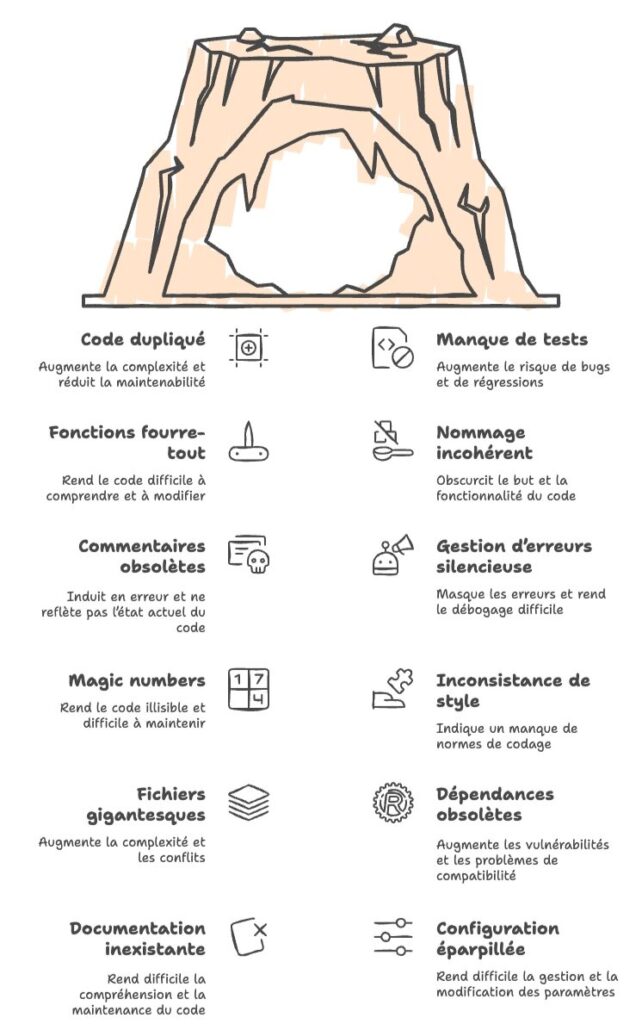
Comment la repérer ?
Dès la prise en main d’un projet, le réflexe devrait être d’identifier ces dettes visibles, souvent causées par le rush initial ou l’absence de pratiques solides. La dette de surface, c’est un ensemble de signaux. Certains sont des classiques qu’on retrouve partout, d’autres sont plus subtils.
Les classiques
On commence par les plus évidents, ceux que vous repérerez dès les premières heures passées dans le code :
- Code dupliqué : ça sent le copier-coller à plein nez, souvent pour accélérer, mais au prix de la maintenabilité.
- Manque de tests : développer sans tests, c’est développer dans le noir. Quand vous corrigez un bug, comment savez-vous que vous n’en créez pas un autre ?
- Fonctions fourre-tout : ce n’est pas une fonctionnalité, c’est un roman. Des fonctions de 500 lignes qui font tout et n’importe quoi.
Les signaux qu’on oublie souvent
Ensuite, il y a des indicateurs plus discrets, mais tout aussi révélateurs. Ce sont souvent eux qui trahissent un projet où la dette s’est installée dans la durée :
- Nommage incohérent ou cryptique : des variables
temp,data,x, des fonctionshandleStuff()qui ne disent rien sur ce qu’elles font. Pire : des nommages qui mentent, comme une fonctiongetUser()qui en fait modifie l’utilisateur. Le nommage, c’est la première documentation du code. - Commentaires obsolètes ou TODOs abandonnés : un
// TODO: fix this laterdaté de 2019, un commentaire qui décrit un comportement qui n’existe plus. Les commentaires fantômes sont un signe que le code a évolué sans que personne ne prenne le temps de nettoyer. - Gestion d’erreurs silencieuse : des
try/catchvides, des erreurs avalées sans log, desprint("error")perdus dans le code. Quand quelque chose plante en prod, vous ne saurez jamais pourquoi. C’est une dette invisible jusqu’au jour où elle explose. - Magic numbers et valeurs hardcodées : des
if (status == 3)ou destimeout = 5000sans explication. Qu’est-ce que3? Pourquoi5000? Ce genre de dette rend le code illisible et dangereux à modifier. - Inconsistance de style : un fichier en camelCase, l’autre en snake_case. Des tabs ici, des espaces là. Ça paraît cosmétique, mais ça révèle souvent un projet où chacun a codé dans son coin sans conventions communes.
Les signaux d’alerte organisationnels
Au-delà du code lui-même, certains signaux relèvent plus de l’organisation du projet. Ils sont souvent le symptôme d’une dette qui s’est accumulée faute de conventions partagées :
- Fichiers ou classes gigantesques : un ViewController de 3000 lignes, un
Utils.swiftfourre-tout où tout le monde ajoute ses fonctions. Ces fichiers deviennent des zones de conflit en équipe et des nids à bugs. - Dépendances obsolètes : des librairies qui n’ont pas été mises à jour depuis des années, des warnings de dépréciation ignorés. Chaque mise à jour repoussée accumule de la dette. Et un jour, la migration devient un projet en soi.
- Documentation inexistante ou mensongère : un README qui décrit une architecture qui n’existe plus, des diagrammes datant de la v1. Une doc obsolète est parfois pire que pas de doc : elle induit en erreur.
- Configuration éparpillée : des constantes définies à trois endroits différents, des URLs d’API hardcodées dans le code, des feature flags gérés n’importe comment. Quand vous devez changer un paramètre et que vous ne savez pas où chercher, c’est de la dette.
Le piège : vouloir tout corriger
Vous venez de lire tout ça et vous avez coché mentalement la moitié des points ? C’est normal. Tous les projets ont de la dette de surface. Le piège, c’est de vouloir tout attaquer en même temps.
Le plus dur quand on arrive sur un projet, c’est de résister à l’envie de tout refaire. On repère des problèmes partout et on veut les corriger immédiatement. Prenez le temps de découvrir. Un fichier n’est pas testé ? Un nommage est bizarre ? Ne vous dites pas automatiquement « il faut corriger ça ». Demandez-vous plutôt : est-ce que c’est la priorité dans le scope actuel ? Est-ce que ça bloque quelque chose ?
L’idée n’est pas de mettre ces problèmes de côté, mais de les noter et les prioriser. Créez-vous une liste, un board, peu importe. Mais ne gardez pas tout en tête. Une fois que vous avez sécurisé les éléments critiques, le reste devient un fil rouge à dérouler au fur et à mesure.
Spoiler : vous trouverez toujours de la dette. L’objectif n’est pas de l’éliminer, c’est de la gérer.
Notre expérience
Dans cette première phase, il ne faut pas penser trop vite que parce que les bugs sont durs à corriger, il faut revoir toute l’application. De notre côté, au bout de 6 mois, on aurait pu se dire qu’il fallait tout refaire, parce que certains bugs prenaient plusieurs jours à être compris et corrigés. Mais avec le recul, prendre le temps de comprendre un bug vous fait visualiser plus largement comment l’éviter par la suite.
Cela permet aussi de créer un maillage de problèmes qui ramènent souvent à des groupements ciblant des parties spécifiques de l’application. On a refait des écrans en fonction de ce constat et commencé à comprendre ce qui posait problème. On a décortiqué les problèmes et surtout on les a documentés, ce qui a permis de classifier les bugs par thématiques et parties de l’application, pour ensuite isoler les parties legacy des nouvelles.
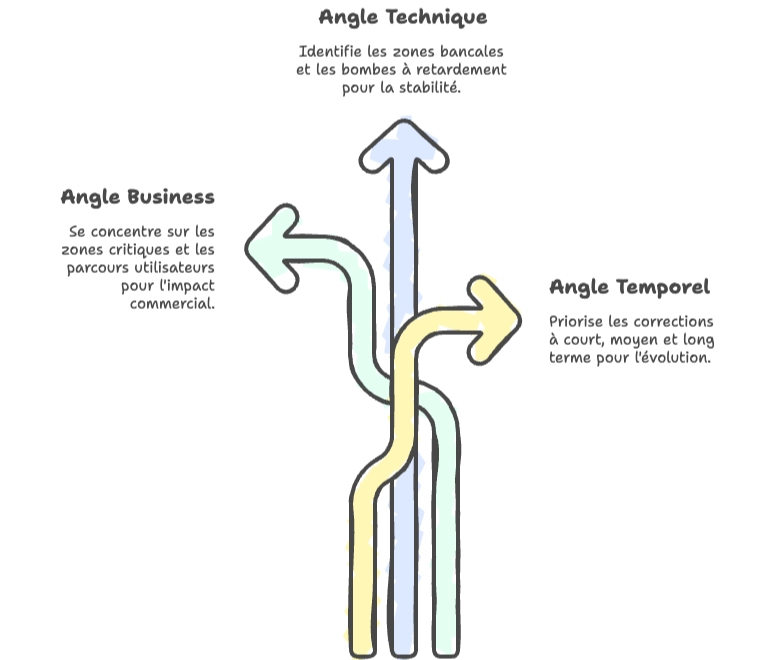
Pour regrouper ces problèmes, vous pouvez utiliser différents angles de vue :
- L’angle business : quelles parties de l’application sont critiques pour l’entreprise ? Où sont les parcours les plus utilisés ?
- L’angle technique : qu’est-ce qui vous semble le plus bancal et dangereux dans le temps ? Quelles parties sont des bombes à retardement ?
- L’angle temporel : qu’est-ce qui doit être corrigé à court terme (bloquant), moyen terme (fragilité), long terme (évolution) ?
Mixez ces angles selon vos besoins. Il n’y a pas de formule magique. C’est votre compréhension du projet qui fera la différence.
Ne jamais refaire l’application de zéro
Dans notre stratégie en équipe, nous avions décidé de ne jamais refaire l’application de zéro. Un challenge pas facile, mais qui nous a fait grandir dans la compréhension des différentes parties. Certaines applications ne pourraient pas appliquer cette stratégie, mais c’est une approche qui m’a fait évoluer dans ma méthodologie pour comprendre du code rapidement et refactoriser en isolant les parties legacy.
Les outils de cette phase
Voici les outils qu’on a mis en place pendant cette première phase, chacun avec un rôle précis dans notre stratégie de réduction de la dette :
| Outil | But / Mission |
|---|---|
| Audit (slides avec screenshots) | Parcourir l’application et faire des retours sur le comportement, que ce soit fonctionnel ou visuel. |
| SwiftLint (linter) | Mettre en place un formalisme de code commun. Mis en place en itération : d’abord quelques règles, puis activation progressive après avoir fixé les précédentes. |
| Logs système | Permettre de mieux debug les erreurs de l’application et mieux remonter ce qui pose problème. |
| Documentation des bugs | Comprendre l’application et réussir à grouper les bugs et les parties qui posent le plus de problèmes pour prioriser les refacts. |
| Firebase Crashlytics | Suivre les crashs en production et prioriser les corrections. |
Le Linter : une mise en place progressive
La première chose qu’on a mise en place à la reprise du projet, c’est SwiftLint pour iOS. On a élaboré une stratégie qui nous a permis d’activer les règles de code petit à petit. Pas tout d’un coup, car le projet était entièrement en rouge. D’abord une ou deux règles prioritaires qui passaient sans trop de modifications. Ensuite, des points réguliers, souvent post-release, pour activer de nouvelles règles au fur et à mesure qu’on corrigeait les précédentes. Cela a permis une amélioration constante et satisfaisante.
C’est là qu’intervient le concept de fil rouge. Une fois qu’un outil est en place, on peut faire du suivi et corriger au fur et à mesure. On se retrouve à faire des petites améliorations constantes plutôt que des gros chantiers intimidants. C’est plus digeste pour l’équipe, et ça crée une dynamique d’amélioration continue.
Firebase Crashlytics : prioriser grâce aux données
On a branché le système de détection de crash dans Firebase Crashlytics pour avoir des remontées des crashs utilisateurs et pouvoir les flaguer une fois corrigés. Ça montre les endroits posant le plus de problèmes et ça aide à prioriser une roadmap en voyant les problèmes et leur fréquence.
Un point important : la dette technique, pour la plupart des gens, ce n’est pas tangible. Il y a une forme de pédagogie à avoir avec les autres équipes pour faire comprendre le niveau de dette d’une plateforme. Si vous proposez des refontes récurrentes sans trop de vision de ce qui ne va pas, il y aura une perte de confiance, et ça peut être dur d’amener d’autres changements ensuite.
Les logs : ne pas négliger le debugging
Pour bien débugger, vous avez besoin de mettre des logs pertinents dans votre application. Ça a été de pair avec Crashlytics, car on a travaillé à faire des remontées Non Fatal des erreurs via Crashlytics. Prenez le temps de mettre ces logs dans les nouvelles parties comme dans les parties legacy.
Conseils pour cette phase
Chaque projet est différent. Prenez le temps d’analyser les choses et ne foncez pas trop vite dans les choix de refaire telle ou telle partie. C’est une question de vision d’entreprise et de discussions avec l’équipe. Trouvez comment aligner tout le monde sur les problèmes.
On a tous envie de mettre en place ce qu’on a vu dans une entreprise précédente, mais se poser et comprendre le code et ses problèmes vous fera adapter vos solutions à la situation plutôt que d’appliquer quelque chose de générique. Chaque entreprise est différente, chaque projet est différent, et surtout l’humain est important.
Ne vous battez pas pour une solution. Exposez les problématiques, les différents choix qui s’offrent à vous, notez les avantages et inconvénients. Vous verrez, le choix collectif sera plus facile. Et si vous vous retrouvez seul face à l’équipe sur un choix de refactoring, ne vous découragez pas. Proposez plutôt de poser les choses à plat : est-ce que tout le monde a bien compris le problème remonté ? Son impact ?
À retenir
La découverte d’un projet, que l’on soit junior ou expérimenté, commence toujours par apprendre. Apprendre comment fonctionne l’application, mais pas que. Apprenez aussi à connaître les personnes avec qui vous travaillez : qui connaît quelle partie du code ? Qui a l’historique des décisions passées ?
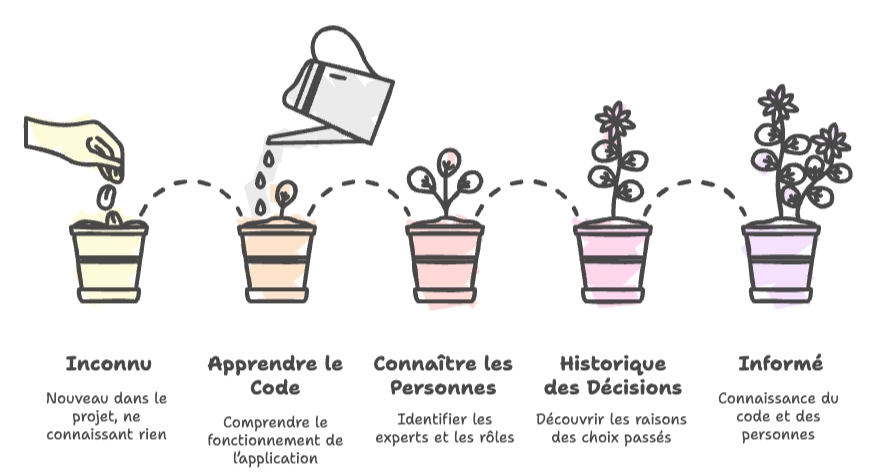
Cette phase est cruciale pour poser les bases d’une gestion saine de la dette technique. Le code, c’est une chose. Les humains qui le maintiennent, c’en est une autre. Et les deux comptent autant.
Pour poursuivre la série, rendez-vous sur le prochain volet qui explore la dette profonde et structurante, et comment adapter l’architecture sans tout casser.
Résumer cet article avec :


