
Comment résorber sa dette technique : opérer sans tout casser (partie 2)

Une fois qu’on connaît mieux un projet, on peut commencer à se projeter. Pour nous, ça a été au bout d’un an et demi. On a commencé à penser à comment adapter l’architecture cœur vers quelque chose qui nous faciliterait la vie dans le contexte de notre application. Ce deuxième volet passe de la découverte à la compréhension : après la dette de surface (partie 1), on s’attaque ici à la dette profonde et structurante, avant de conclure sur la dette cachée dans la partie 3.
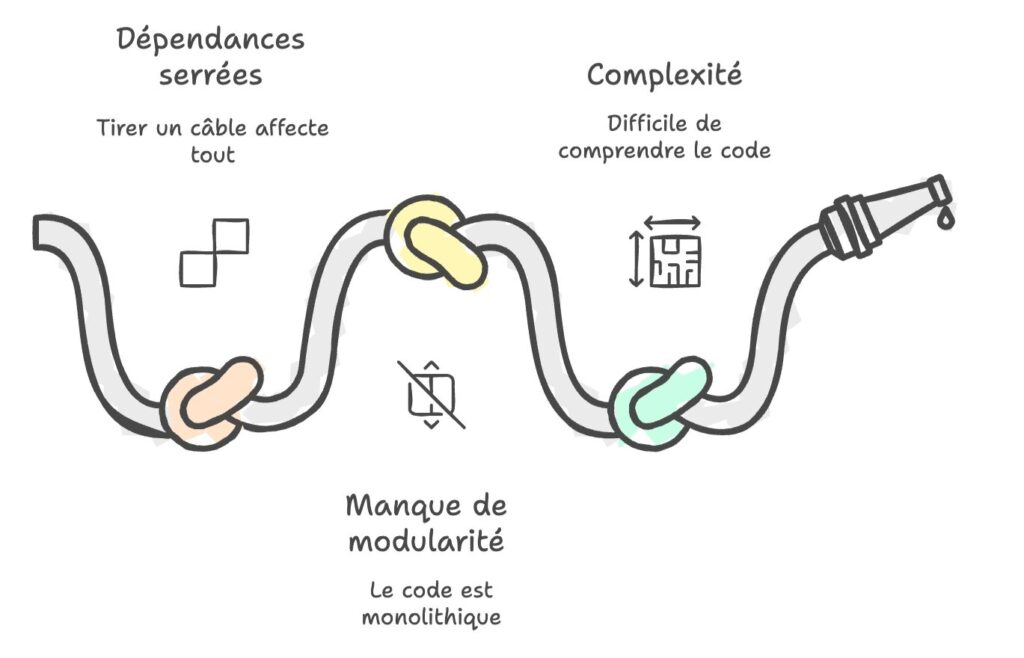
C’est quoi, la dette profonde ?
La dette profonde, c’est celle qui est ancrée dans l’architecture du projet. C’est le choix technologique qu’on a fait pour aller vite, mais qui revient nous hanter. Un service monolithique qui n’évolue plus, des dépendances non maîtrisées, une API centrale qui devient un goulot d’étranglement.
Comment on la débusque ?
Détecter la dette profonde exige une compréhension globale du projet. Contrairement à la dette de surface qui saute aux yeux, celle-ci se révèle avec le temps, quand vous commencez à vraiment comprendre comment les pièces s’assemblent.
Les signaux
Voici les indicateurs qui doivent vous mettre la puce à l’oreille. Si vous en reconnaissez plusieurs, c’est probablement que la dette profonde est déjà bien installée :
- Cartographiez votre architecture : quelles sont les dépendances critiques ? Quels modules créent des goulots d’étranglement ? Si vous n’arrivez pas à dessiner un schéma clair de votre architecture, c’est déjà un signal.
- Couplage fort entre modules : quand toucher un module oblige à en modifier trois autres. Les dépendances sont tellement imbriquées qu’on ne sait plus où commence une feature et où elle finit.
- Absence de couches d’abstraction : le code UI qui appelle directement la base de données. Les appels réseau éparpillés partout. Pas de séparation claire entre la logique métier et le reste.
- God classes et monolithes internes : ce manager de 5000 lignes qui fait tout. Ce singleton appelé depuis 200 fichiers. Ces classes deviennent impossibles à faire évoluer sans tout casser.
- Écoutez les plaintes récurrentes : si chaque nouvelle fonctionnalité casse trois autres modules, il y a un problème structurel. Si l’équipe dit souvent « on ne peut pas faire ça à cause de X », notez ces X.
- Temps de développement qui explose : une feature simple qui prend des semaines. Des estimations toujours dépassées. Ce n’est pas forcément un problème de compétence, c’est souvent la dette qui freine.
- Peur de toucher certaines parties : ces zones du code que tout le monde évite. « On ne touche pas à ça, ça marche. » C’est un signe que la dette est devenue trop coûteuse à adresser.
- Bugs récurrents au même endroit : vous corrigez un bug, il revient sous une autre forme. Le problème n’est pas le bug, c’est la structure qui le permet.
- Dépendances circulaires : A dépend de B qui dépend de C qui dépend de A. Ces cycles rendent le code impossible à tester et à faire évoluer proprement.
Notre expérience : repenser l’architecture
Quand on parle d’architecture, on peut vite tomber dans un piège : choisir une approche parce qu’elle est tendance, parce que c’est « ce qui se fait », ou parce qu’on l’a vue dans une conférence. C’est une erreur. L’objectif n’est pas d’adopter la dernière architecture à la mode, mais de trouver celle qui répond aux besoins de votre projet, votre équipe, et votre contexte.
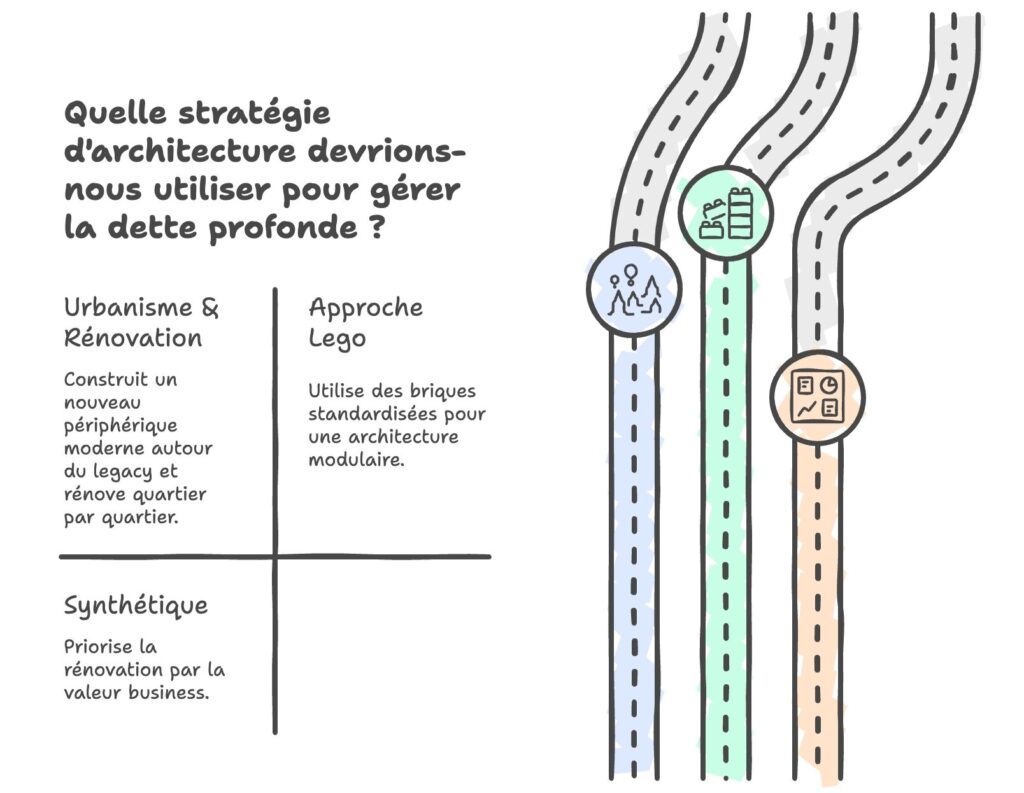
Nous avons discuté de plusieurs architectures : VIPER, MVI, MVVM. Notre prérequis était clair : pas question d’appliquer une architecture « clé en main » parce qu’elle était populaire. On voulait quelque chose qui puisse s’adapter à nos réalités : ne pas nous obliger à utiliser toute la mécanique pour un simple écran statique, mais conserver une ligne directrice cohérente sur l’ensemble du projet.
On a expérimenté et trouvé un mélange de MVVM/MVI avec des Coordinators et de la Clean Archi (DomainLayer, UseCase, DataLayer, Repository, etc.). L’idée était de fournir des objets clés utilisables selon les besoins. Le résultat :
- Des features isolées et scalables en termes d’architecture
- Certains parcours avec une architecture un peu plus évoluée selon les besoins
- Un socle autour des Coordinators pour gérer les workflows et pouvoir les lancer de façon standalone
Intégrer la nouvelle architecture dans le legacy
Le plus dur n’est pas de trouver l’architecture, mais de l’intégrer dans le projet existant avec du code legacy.
On a installé le socle de base de la navigation de niveau 0 dans un premier temps, en laissant toutes les features actuelles utiliser l’ancien système. On avait une TabBar au niveau 0, on s’est concentrés là-dessus. Ensuite, on a priorisé selon les enjeux business pour revoir les architectures de chaque partie. C’est une phase qui n’est pas facile, car il faut d’un côté opérer ce changement, et de l’autre garder en tête une stratégie pour les parties qui n’ont pas encore été traitées.
Bien noter ce qui ferait sens en fonction des enjeux business pour glisser des évolutions petit à petit, c’est essentiel. Essayez autant que possible de finir un chantier avant d’en entamer un nouveau. Sinon, avec une charge mentale importante, vous risquez de perdre le recul nécessaire pour adapter votre stratégie au fur et à mesure.
Adapter l’architecture selon les besoins
Parfois, certaines parties de votre application ont besoin d’une architecture un peu différente pour fonctionner correctement. Et c’est OK.
Ça a été notre cas pour les parcours avec des formulaires complexes : collecte d’informations utilisateur, validations venant du backend, structure pouvant évoluer avec les enjeux légaux. On a dû concevoir une architecture spécifique en s’inspirant de patterns existants, tout en veillant à ce qu’elle se branche proprement au reste de notre socle.
On peut très bien avoir différentes architectures dans un même projet, si c’est justifié. Les architectures que vous connaissez (MVC, MVVM, VIPER, etc.) ont toutes été créées pour répondre à un besoin précis. L’important, c’est d’avoir une ligne directrice commune et de documenter pourquoi certaines parties divergent.
Les outils de cette phase
Dans cette phase de compréhension, on a ajouté des outils qui permettent de prendre du recul et de mesurer l’état réel du projet :
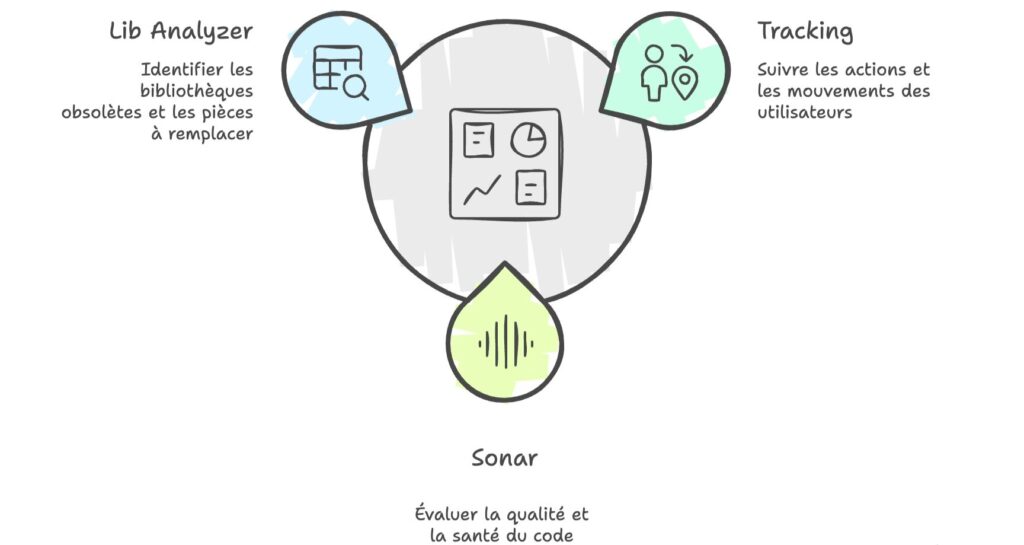
| Outil | But / Mission |
|---|---|
| Tracking | Comprendre les comportements utilisateurs et voir les parcours problématiques. Essentiel pour comprendre les enjeux business et prioriser les améliorations techniques en les alignant avec les priorités de l’entreprise. |
| SonarQube | Analyser la qualité globale du code et suivre les indicateurs de dette technique dans le temps. |
| Visualisateur de librairies | Vérifier les librairies utilisées, faire un état des lieux, et voir si certaines peuvent être remplacées ou ont un impact fort sur le code core. |
Le Tracking : comprendre les enjeux business
On a mis en place le Tracking. Certes, c’est souvent vu comme un outil marketing, mais on a voulu en profiter pour comprendre les usages de nos utilisateurs. Comme dans la phase précédente avec les crashs, ici on affine les recherches pour identifier plus précisément les problèmes de l’application.
On a couplé le Tracking avec les Crash et NonFatal dans Firebase Crashlytics. Résultat : on peut savoir ce que l’utilisateur a fait dans les instants précédant un problème. C’est précieux pour le debug. On a aussi conçu notre Tracker pour être modulaire : il peut partager les données de tagging à plusieurs outils en même temps, que ce soit pour l’analyse marketing ou pour le debug technique.
Je recommande d’y aller par étapes : mettre en place des outils détaillés alors que votre application présente déjà des problèmes majeurs visibles ne vaut peut-être pas le coup. Cela peut même vous surcharger de travail sur la dette, plutôt que de vous aider.
SonarQube : centraliser les métriques
On a intégré SonarQube, qui s’inscrit dans la continuité du Linter, mais avec des règles supplémentaires et une centralisation pour les vérifications lors des PRs. L’avantage de la centralisation, c’est qu’on peut observer l’évolution à travers le temps.
Attention aux indicateurs de façade : prenez le temps de voir avec l’équipe quels indicateurs permettront de comprendre que l’application s’améliore réellement. Il n’y a rien de pire que de voir des indicateurs qui ne correspondent pas à ce que l’on fait au quotidien.
Visualisateur de librairies : anticiper les blocages
C’est un sujet qu’on néglige souvent, et pourtant il peut devenir critique. Une librairie dépréciée, une dépendance qui bloque une montée de version d’OS, une lib qui n’est plus maintenue… et soudain, vous êtes bloqués. Le business attend une feature, mais vous ne pouvez pas avancer sans d’abord régler ce problème technique.
L’idée, c’est d’anticiper. Faites régulièrement un état des lieux de vos dépendances :
- Librairies dépréciées : est-ce qu’une lib que vous utilisez n’est plus maintenue ? Plus vous attendez, plus la migration sera douloureuse.
- Blocages de montée de version : certaines libs peuvent vous empêcher de passer à une nouvelle version d’iOS ou Android. Si vous ne les identifiez pas à l’avance, vous découvrirez le problème au pire moment.
- Libs structurantes vs libs remplaçables : une lib d’UI, ça se remplace. Une lib de navigation utilisée partout, c’est un chantier de plusieurs mois. Identifiez lesquelles sont critiques.
- Licences et sécurité : des libs avec des failles de sécurité connues ou des licences incompatibles peuvent devenir des bombes à retardement.
Un point important : un choix de lib pertinent à un instant T peut devenir obsolète avec le temps. C’est exactement ce qu’on a vécu avec l’arrivée de Compose et SwiftUI côté mobile. Des solutions qu’on avait choisies sont devenues legacy. On ne peut pas tout faire d’un coup. On note tout, on partage avec l’équipe, et on se coordonne pour prioriser ensemble. Le pire scénario, c’est de découvrir qu’une lib bloque tout le jour où vous devez livrer une feature importante. Anticipez.
Conseils pour cette phase
Dans cette phase de compréhension globale, vous aurez peut-être l’impression d’être sur tous les fronts. Prenez bien le temps de corriger un maximum de remontées à chaque outil ajouté, afin de garder un rythme de fond.
Laissez-vous la possibilité d’évoluer dans la façon dont vous gérez les outils dans votre quotidien. Un outil et une façon d’interagir avec lui ne seront pas les mêmes dans cette phase que dans la précédente, ni dans la suivante. Votre compréhension et vos besoins vont évoluer.
À retenir
Cette phase demande de la patience et de la rigueur. Les choix architecturaux que vous faites ici auront un impact durable sur la maintenabilité de votre projet. Prenez le temps de bien les réfléchir et de les aligner avec les enjeux business de votre entreprise.
Ce deuxième volet prépare le terrain pour le final de la série. Si ces chantiers d’architecture résonnent avec votre contexte, la prochaine étape consiste à rendre visible la dette cachée et à la piloter sereinement.
Résumer cet article avec :


