Comment nous avons créé notre algorithme de prédiction de régularisation d’impayé chez Leocare

Résumer cet article avec :
Dans le secteur de l’assurance, la gestion des impayés est un défi opérationnel et financier majeur. Chaque rejet de prélèvement perturbe le cycle financier et engage des ressources considérables. Chez Leocare, nous disposions de relances automatisées (CRM) et la possibilité de régénérer une nouvelle tentative de paiement directement sur la carte bancaire, mais nous manquons d’une capacité d’intervention humaine directe.
Pourtant, il y a un coût : chaque dossier non régularisé entraîne la résiliation du contrat d’assurance
Face à un montant non satisfaisant de rejet de prélèvements il est devenu évident que nous devions introduire une nouvelle action : le rappel téléphonique. Mais l’action humaine est coûteuse. L’enjeu n’était donc pas de tout relancer, mais de relancer juste. L’incertitude est notre principal adversaire. Certaines situations se résolvent spontanément, tandis que d’autres nécessitent une intervention humaine pour éviter la perte définitive du contrat. Notre objectif n’était pas d’optimiser une capacité existante, mais de la créer de toute pièce en la rendant immédiatement efficace.
Après avoir constaté l’insuffisance des méthodes classiques (relances CRM seules, segmentation statique), nous avons fait le pari de la Data Science. Notre défi était de déterminer si les données dont nous disposons (historique client, le contexte bancaire, la nature du contrat) permettaient de prédire la probabilité de régularisation d’un impayé dans le délai contractuel de 40 jours. Cette intuition a marqué le début d’un travail méthodique visant à formaliser un problème prédictif solide et exploitable en production. Le modèle que nous avons construit a permis de créer un score de priorité, servant de socle à la mise en place d’une nouvelle capacité d’appel téléphonique qui maximise l’impact de chaque conversation.
Le point de départ : comprendre l’impayé et accepter l’incertitude
Avant même d’aborder la modélisation, nous devions reconnaître la complexité intrinsèque du phénomène. Un impayé n’est jamais un incident isolé. Il s’inscrit dans une trajectoire comportant des facteurs humains, techniques, bancaires et contractuels. Chaque rejet peut découler d’une réalité différente : un solde insuffisant, une contrainte ponctuelle, une évolution de la situation du client, une insatisfaction, de la fraude, une particularité bancaire ou encore un décalage dans nos systèmes.
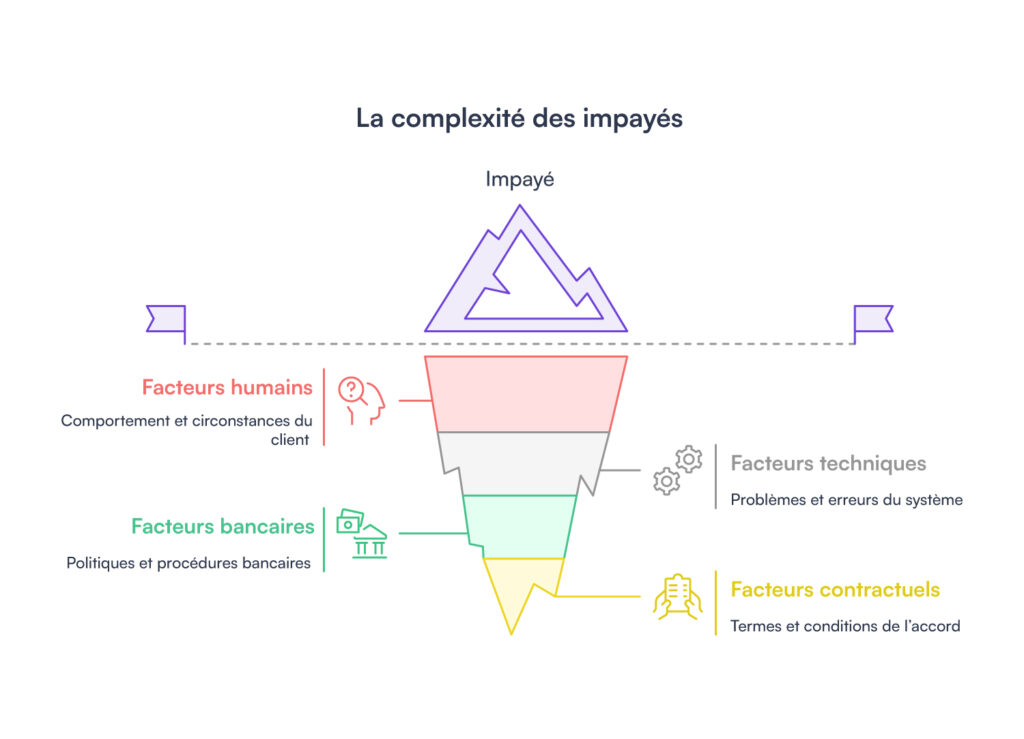
Très tôt, nous avons dû accepter une contrainte structurante : certaines informations, bien que pertinentes, ne sont accessibles qu’en décalé. Les données sur lesquelles nous nous appuyons ne sont disponibles qu’à J+1 dans notre datawarehouse, ce qui signifie que certaines régularisations ou tentatives ne sont visibles qu’après coup. De plus, les modalités de paiement, notamment les différences entre CB et IBAN, impliquent des comportements et des historisations distinctes.
Cette prise de conscience nous a obligés à adopter une approche prudente mais déterminée. Chaque hypothèse devait être vérifiée empiriquement, car l’incertitude fait partie intégrante de la dynamique des impayés.
Nous avons rapidement compris que nos premières intuitions seraient mises à l’épreuve par la question de savoir si les données porteraient suffisamment d’information pour permettre la construction d’un modèle performant. Nous nous sommes alors appuyés sur les équipes métiers afin qu’elles nous aident à identifier les variables importantes selon leur expertise, pour ne passer à côté de rien.
Un autre obstacle important relevé dans les documents concernait les limites du système d’information. Certains signaux que nous aurions souhaité exploiter n’existaient tout simplement pas dans nos bases. D’autres n’étaient pas historisés, ou seulement partiellement. Nous devions donc accepter que notre compréhension du phénomène serait contrainte par le périmètre exact des données disponibles.
Enfin, nous avons dû composer avec un paradoxe : l’impayé est fréquent, mais sa dynamique est difficile à généraliser puisqu’il est rétroactif (jusqu’à 12 mois après le prélèvement, ce qui ajoute un risque résiduel). Les trajectoires sont variées, parfois contradictoires. Certaines régularisations surviennent en quelques jours, d’autres au dernier moment du délai contractuel, d’autres encore jamais. C’est cette diversité qui nous a obligés à penser le problème non pas comme une simple classification, mais comme une tentative de lecture de trajectoires behaviorales dans un système où l’information n’est jamais parfaite.
Cette première phase a donc été bien plus que l’identification d’un problème. Elle a constitué une remise à plat de nos représentations. Nous avons dû accepter de ne pas tout maîtriser, de nous laisser guider par la donnée, et d’apprendre à questionner nos intuitions. Cette humilité méthodologique est devenue le socle sur lequel tout le reste du projet s’est construit. Nous avons ainsi construit les fondations d’une démarche analytique ancrée dans la réalité opérationnelle, consciente de ses limites mais structurée pour progresser.
Définir la cible : un travail fondamental
Définir la cible a été l’un des moments les plus délicats et les plus structurants du projet.
À première vue, l’objectif semblait simple : prédire qu’un impayé serait ou non régularisé. Mais dès que nous avons commencé à explorer les données et à comprendre les flux contractuels, nous avons réalisé que la question devait être beaucoup plus précise. La modélisation ne visait pas seulement à anticiper la régularisation, mais surtout à trier les individus : identifier ceux pour lesquels une relance téléphonique serait pertinente et éviter de mobiliser inutilement les équipes sur les cas susceptibles de se régulariser spontanément.
Ainsi, le choix de la fenêtre de 30 jours n’a pas été arbitraire. Il s’est imposé à nous au croisement de plusieurs contraintes évoquées.
D’abord, la mécanique contractuelle. Une quittance impayée suit un cycle strict, balisé par des délais réglementaires au-delà desquels le statut du contrat évolue. Après 30 jours, les mécanismes de suspension et les relances obligatoires modifient entièrement la dynamique du dossier. Tenter de prédire une régularisation au-delà de cette fenêtre n’aurait pas correspondu à la réalité opérationnelle. À l’inverse, une fenêtre plus courte aurait été trop réductrice et n’aurait pas capturé les nombreux cas où les clients régularisent naturellement juste avant le seuil contractuel.
Ensuite, l’analyse statistique. Lorsque nous avons examiné les distributions temporelles de régularisation, un pattern clair est apparu : la grande majorité des paiements se résolvent dans les premiers 30 jours. Les rares cas de régularisation tardive ne constituent pas un signal exploitable, mais plutôt des exceptions dictées par des situations particulières ou des processus externes. Cette observation, bien qu’intuitive pour les équipes métier, a trouvé une confirmation solide dans les données.
Enfin, nous avons choisi de ne considérer que le premier rejet de prélèvement pour chaque quittance. Pour rappel, une quittance correspond à un document officiel attestant qu’un client doit régler un paiement pour une période donnée (souvent un mois de loyer ou de contrat). Si le client ne paie pas à la première présentation, la même quittance peut être présentée plusieurs fois, parfois avec un délai d’un mois ou plus entre les tentatives. Nous avons retenu uniquement le premier rejet, car c’est le plus pertinent d’un point de vue métier et cela évite de diluer les signaux. Le premier rejet marque le basculement d’un client régulier vers une situation d’impayé, moment où le comportement futur devient incertain (exactement ce que nous voulions analyser). D’autres repères temporels ont été envisagés, mais aucun n’offrait la même cohérence analytique.
Cette réflexion nous a aussi confrontés à une autre problématique : l’arbitrage entre précision théorique et applicabilité métier. La définition trop complexe d’une cible aurait rendu le modèle difficile à expliquer, donc difficile à utiliser. À l’inverse, une définition trop simplifiée aurait conduit à une perte de sens opérationnel. Le compromis choisi par la probabilité de régularisation dans les 30 jours suivant un premier rejet de quittance nous a permis de garder une logique à la fois prédictive, interprétable et liée directement aux contraintes légales comme aux besoins des équipes terrain.
Ce travail de cadrage nous a appris que la cible n’est pas un paramètre technique parmi d’autres. C’est la colonne vertébrale du modèle, celle qui détermine son utilité réelle. Cette étape a posé les fondations méthodologiques de tout ce que nous avons construit ensuite.
La donnée : structuration, enrichissement et limites
Lorsque nous avons commencé à explorer nos données, nous savions que la réussite du modèle dépendrait presque entièrement de la qualité, de la cohérence et de la profondeur des informations disponibles. Il ne s’agissait pas seulement d’assembler des tables, mais de comprendre ce qu’elles révélaient, ce qu’elles omettaient et comment leurs imperfections pouvaient influencer notre capacité à prédire. Pour ce travail, nous nous sommes appuyés sur les équipes métier.
L’une des premières difficultés a été d’admettre que certaines informations intuitivement pertinentes, comme l’intention du client, la nature exacte de sa contrainte financière ou les raisons profondes d’un rejet, n’existent tout simplement pas sous une forme exploitable. Les motifs bancaires ne sont pas toujours disponibles, les interactions humaines ne sont pas historisées de manière uniforme, et certains signaux ne laissent aucune trace numérique. Il a donc fallu fonder notre modèle sur des variables réellement observables, et non sur celles que nous aurions souhaité posséder.
À partir de cette prise de conscience, nous avons entrepris un travail de consolidation minutieux. Les données contractuelles nous ont permis de caractériser la nature du contrat, son ancienneté et sa conformité. Les données clients ont révélé l’historique de la relation, le nombre de contrats détenus et les précédents incidents de paiement. Côté bancaire, la structure de l’IBAN et du BIC a offert des perspectives inattendues : la longueur de l’IBAN, son pays d’origine ou la typologie de la banque permettaient de détecter des tendances comportementales invisibles dans un jeu de données purement transactionnel. Bien évidemment, traiter des données bancaire est un sujet sensible donc on a bien veillé à ce que l’ensemble de ce travail soit conduit dans le respect du RGPD, en utilisant exclusivement des données anonymisées afin de garantir la confidentialité des informations personnelles.
Il a ensuite fallu transformer notre dataset pour le rendre exploitable : gestion des valeurs aberrantes, traitement des données manquantes, et réconciliation des informations provenant de différentes sources, notamment les rejets de prélèvement liés à un IBAN ou à une carte bancaire, car les clients peuvent utiliser les deux modes de paiement. Nous avons alors pu entreprendre la construction des variables dérivées qui a été un travail fondateur. Elle a permis de rendre visibles des phénomènes qui ne l’étaient pas dans la donnée brute et de créer une représentation cohérente du phénomène, racontant l’histoire des impayés à travers les traces numériques laissées par les processus.
Une fois le dataset nettoyé et les variables dérivées construites, nous avons procédé à une exploration approfondie des données. Des analyses statistiques et de corrélation ont identifié les variables les plus pertinentes pour expliquer la régularité des quittances et ont permis de détecter les redondances dans le dataset.
C’est cette narration silencieuse des données qui a servi de socle à tout le travail de modélisation.
Les premières modélisations : performance statistique et limites opérationnelles
Lorsque nous avons lancé les premières modélisations, nous étions à un moment charnière du projet : celui où la théorie rencontre enfin la réalité des données. Après des semaines d’assemblage, de nettoyage, de construction de variables dérivées et de reconstitution des trajectoires, nous allions vérifier si les signaux que nous pensions détecter existaient réellement. Les premiers résultats ont suscité un mélange de soulagement, de surprise et de frustration.
Nous avons testé différents types de modèles : des modèles d’arbres en ensemble (Random Forest, Boosting) et des modèles plus simples comme les arbres de décision (CART). Tous ont produit des performances intéressantes, ce qui montrait que les données portaient effectivement des informations exploitables.
Compte tenu du déséquilibre de la variable cible, nous avons évalué les performances avec des métriques adaptées : F1-score, rappel, précision et AUC. Ces scores ont confirmé que certains comportements n’étaient pas aléatoires : la régularisation des impayés n’était pas un phénomène purement chaotique. C’était un vrai soulagement, car l’un de nos plus grands doutes au départ était de ne rien trouver.
Mais presque immédiatement, un problème majeur est apparu : la quasi-totalité du signal provenait d’une seule variable, l’historique des impayés. Cette variable dominait tous les modèles testés, et les algorithmes complexes se concentraient presque exclusivement sur elle, au détriment des autres informations. En pratique, le modèle se contentait d’une règle triviale : un client ayant déjà eu des impayés a plus de chances de ne pas régulariser. Les autres signaux, pourtant pertinents, se retrouvaient écrasés et perdaient toute visibilité dans le modèle.
Statistiquement correcte, cette règle était cependant peu utile opérationnellement. En effet, l’objectif était d’optimiser les relances : identifier les clients ayant des probabilités plus faibles de régulariser seuls afin de concentrer les appels sur eux. Avec un modèle dominé par l’historique des impayés, nous aurions été contraints de rappeler uniquement les clients dont ce n’était pas le premier échec de prélèvement, ce qui aurait limité l’efficacité de l’action.
Ainsi, malgré les scores encourageants, nous avions l’impression d’avoir construit un modèle qui n’était pas utile opérationnellement. C’est ici que nous avons été face à une leçon fondamentale : statistiquement bon ne veut pas dire opérationnellement utile. Un modèle peut être performant selon des métriques classiques tout en étant inutilisable. Cette prise de conscience nous a obligés à revoir entièrement notre approche. Pour produire un outil réellement utile aux équipes, il fallait révéler des signaux que ce modèle ne voyait pas encore, et pour cela, il fallait reconsidérer la manière même dont on structurait la population.
Ce fut le début d’un changement conceptuel qui allait transformer la suite du projet : la réalisation que deux dynamiques comportementales coexistaient réellement, et que tenter de les modéliser ensemble revenait à brouiller le signal. Cette intuition, alimentée autant par les données que par les retours métiers, nous a conduits à un choix méthodologique structurant : scinder la population en deux modèles distincts.
Construire deux modèles : une décision structurante
Au début du projet, notre approche était simple et séduisante : un modèle unique capable de prédire les impayés pour l’ensemble de la population. Cette solution centralisée semblait facile à maintenir et à déployer. Rapidement, la réalité statistique est venue tempérer cet enthousiasme : l’historique des impayés dominait tellement les données que le modèle se focalisait presque exclusivement sur cette information, au détriment des nuances comportementales. La logique qui s’imposait était finalement le cas de la personne « qui a déjà eu des impayés risque d’en avoir encore ».
Cette limite est devenue particulièrement évidente pour les clients en primo-rejet, ceux qui connaissent leur premier incident de prélèvement. Pour eux, le modèle prédisait systématiquement une forte probabilité de régularisation, alors que l’expérience terrain montrait que tous les primo-rejets ne se valent pas : certains sont anecdotiques et se régularisent rapidement, tandis que d’autres annoncent des difficultés durables. Le modèle global ne parvenait pas à distinguer ces situations.
Après discussions approfondies avec les équipes métier, nous avons choisi de scinder la population en deux groupes distincts, chacun faisant l’objet d’une modélisation spécifique :
- les primo-rejets, pour lesquels l’historique est inexistant et les comportements difficiles à anticiper
- les clients ayant déjà connu des impayés, pour lesquels le modèle peut exploiter un historique riche
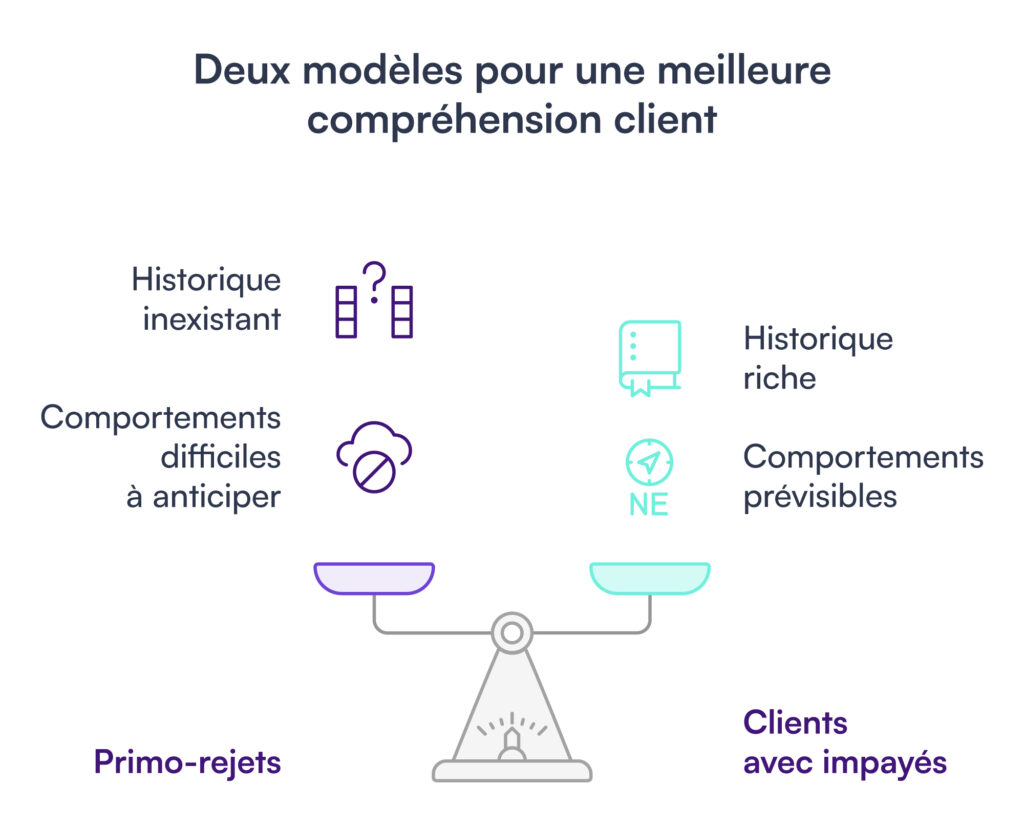
Cette séparation n’a pas été un simple ajustement technique, mais un véritable tournant conceptuel. Elle a permis de mieux refléter la diversité des comportements clients et de construire une logique d’intervention plus fine et efficace. Plutôt qu’une complexité supplémentaire, deux modèles distincts se sont imposés comme la solution évidente pour capturer la richesse des trajectoires clients.
Nous avons ainsi développé deux modélisations spécifiques, qui ont rapidement montré une meilleure performance globale que le modèle unique initial. Cette approche a révélé des signaux jusque-là invisibles : chez les primo-rejets, le modèle identifie des indices permettant de prédire les clients susceptibles de ne pas régulariser leur impayé, tandis que chez les clients récurrents, il met en évidence des signaux indiquant si la régularisation se fera de manière autonome.
Ainsi, le modèle des primo-rejets a fait émerger des éléments auparavant invisibles : certaines banques, temporalités, structures d’IBAN ou signaux contractuels sont devenus pertinents. Les comportements sont devenus lisibles, révélant plutôt qu’écrasant la diversité des situations. Le modèle des clients récurrents a, quant à lui, pleinement exploité l’historique des impayés, qui s’est révélé un indicateur puissant, reflétant naturellement les trajectoires répétitives.
Nous avons testé différents types de modèles, allant des ensembles complexes (comme le Random Forest ou le Boosting) aux algorithmes plus simples. Les résultats ont rapidement confirmé que des modèles simples et interprétables, tels que les Arbres de Décision (CART), suffisaient amplement, sans aucune perte significative de performance prédictive par rapport à leurs homologues plus complexes. Ce choix était stratégique : en optant pour le modèle CART, nous privilégions la transparence et l’interprétabilité. Un arbre de décision se résume à une série de questions logiques de type “si/alors” (par exemple : si le client est un primo-rejet et si le montant est supérieur à X), ce qui le rend directement compréhensible par les équipes métier. Cette simplicité n’est pas qu’un avantage technique ; elle est essentielle pour l’adoption, transformant le modèle en un outil lisible et de confiance, sans sacrifier l’efficacité.
Avec cette approche, nous avons cessé de forcer les données à suivre nos attentes et avons laissé émerger leurs propres structures. Le résultat n’a pas été seulement technique : il a marqué un changement de paradigme, permettant de considérer les impayés comme un ensemble de dynamiques distinctes, chacune avec ses signaux et ses logiques propres.
Ce choix stratégique et méthodologique a jeté les bases d’un pipeline plus intelligent, d’une interprétabilité renforcée et d’une pertinence métier retrouvée, ouvrant la voie à l’industrialisation du modèle.
Le passage en production pour industrialiser et utiliser le modèle
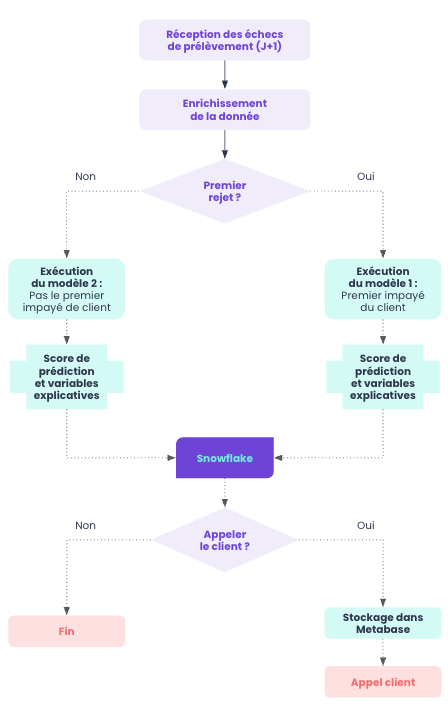
Industrialiser notre approche a constitué une phase décisive, bien plus complexe que ce que nos premiers échanges laissaient imaginer. Nous disposons désormais de deux modèles performants, interprétables et cohérents avec les dynamiques métiers. Mais un modèle seul ne suffit jamais : il doit s’inscrire dans un système vivant, capable de s’adapter aux rythmes et aux contraintes réelles de l’organisation.
La première contrainte majeure concerne la latence de notre datawarehouse (Snowflake) : les données n’étaient disponibles qu’avec un décalage d’un jour (J+1). Aucun rejet ne remontait en temps réel. Cela impliquait que notre pipeline devait fonctionner selon un cycle quotidien strict. Chaque matin, il devait identifier les rejets survenus la veille, déterminer s’il s’agissait d’un primo-rejet ou d’un rejet récurrent, reconstruire les variables dérivées, appliquer le modèle adapté et générer un score exploitable avant même le début de la journée des équipes métier.
Cette contrainte a rapidement révélé de nombreux défis techniques classiques liée à la mise en production de modèles : certaines tables comportaient des valeurs manquantes ou des décalages ponctuels. Pour y faire face, nous avons renforcé la robustesse du pipeline, introduit des contrôles intermédiaires et des garde-fous, afin qu’aucun incident technique ne se traduise par l’absence de score le matin.
La mise en production met également en lumière l’importance cruciale de l’adoption métier. Un score n’a de valeur que s’il est utilisé. Les équipes de recouvrement ne peuvent pas appeler tous les clients ; elles disposent d’un volume limité d’appels. L’objectif de la modélisation était donc de prioriser efficacement : exclure les clients susceptibles de régulariser spontanément et concentrer les efforts sur ceux dont l’intervention humaine a un réel impact.
Pour cela, nous avons travaillé étroitement avec les équipes métier afin de combiner prédiction statistique et choix opérationnels. Nous avons découpé la population en segments mêlant typologie de rejet et probabilité de régularisation, pour générer une liste priorisée des clients à contacter. Cette liste devait être claire, exploitable et intégrée dans Metabase, notre outil de BI self-service. Les équipes peuvent ainsi consulter chaque matin le score, visualiser le segment correspondant et savoir immédiatement si le client nécessite un rappel.
Pour mesurer l’efficacité réelle des priorisations et des campagnes d’appels, nous avons réalisé des A/B tests sur ces segments. Cela nous a permis d’évaluer concrètement l’impact des relances téléphoniques et d’ajuster la stratégie, en nous assurant que les efforts étaient concentrés sur les clients dont l’intervention humaine fait réellement la différence.
Un autre défi important concernait la confiance. Le modèle entrait dans un environnement où les pratiques étaient établies depuis longtemps. Pour qu’il soit adopté, il devait démontrer sa fiabilité jour après jour. La performance en production étant similaire à celle observée à l’entraînement, nous avons pu instaurer ce climat de confiance. Cela a impliqué un suivi fin du pipeline, un monitoring détaillé des volumes, des distributions, des valeurs manquantes et des prédictions elles-mêmes.
Au final, la mise en production n’a pas été une simple étape technique ou logistique. Elle a été l’occasion de rendre le modèle vivant et utile au métier : un outil capable d’accompagner les décisions humaines, de s’adapter aux contraintes opérationnelles et d’optimiser l’efficacité des équipes de recouvrement. C’est dans cette confrontation à la réalité du terrain que nous avons pleinement mesuré la valeur de ce que nous avions construit : non pas une machine autonome, mais un instrument au service des décisions métier.
Nos enseignements, les résultats et les (belles) perspectives
La dernière étape du projet a permis de tirer des enseignements techniques, méthodologiques et opérationnels. La construction d’un modèle prédictif ne se limite jamais à la technique : elle repose sur des arbitrages, des ajustements constants et l’acceptation des limites des données. Les incohérences, trous et latences des flux structurent ce que le modèle peut détecter, tandis que certaines tendances cachées, issues notamment des trajectoires clients ou des dérivations bancaires, se sont révélées particulièrement pertinentes. Définir une cible claire (ici la probabilité de régularisation à 30 jours) a été déterminant pour la stabilité, l’interprétabilité et l’utilité métier du modèle.
La scission de la population en deux modèles distincts, primo-rejets et clients récurrents, a permis de mieux refléter la diversité des comportements et de capter des signaux invisibles auparavant. La mise en production a confronté le modèle à la réalité : latences, irrégularités et contraintes métier. La robustesse du pipeline, le suivi des volumes et des prédictions, ainsi que la lisibilité dans Metabase ont été essentiels pour instaurer la confiance et transformer le modèle en outil opérationnel.
Les résultats confirment l’efficacité et l’efficience de cette approche. Sur notre premier segment ciblé pour les appels téléphoniques (représentant environ 43% des impayés), la régularisation estimée a été supérieure de 61% pour les clients appelés versus non appelés. Mais l’efficience est la clé : grâce au modèle, nous avons pu exclure environ 20% des impayés totaux de cette liste d’appels car leur probabilité de régularisation spontanée était supérieure à 65% sur les 30 jours. Concentrer les appels sur les segments où l’intervention humaine fait la différence permet ainsi d’estimer une augmentation relative de 26% de la régularisation globale.
Ce premier test en production est une base solide. Cependant, le modèle n’est pas un aboutissement : c’est un outil vivant, évolutif et opérationnel, capable d’éclairer les décisions humaines sans jamais les remplacer. Nous continuons d’ailleurs à affiner nos seuils de scoring sur différents segments afin de limiter au maximum le volume d’appels tout en maximisant le gain potentiel, garantissant ainsi l’allocation optimale des ressources humaines.
Ce projet a transformé notre manière de considérer les impayés : non plus comme des incidents isolés, mais comme des trajectoires interprétables. Il a permis de prioriser les relances, d’optimiser les ressources et de maximiser l’impact des interventions humaines, tout en renforçant la collaboration entre équipes métier, finance, recouvrement et data. Le modèle n’est pas un aboutissement : c’est un outil vivant, évolutif et opérationnel, capable d’éclairer les décisions humaines sans jamais les remplacer.
Pour finir…
Notre travail n’a pas seulement produit un modèle, mais une transformation profonde de notre rapport aux impayés. En chemin, nous avons compris que modéliser un phénomène aussi mouvant ne consiste pas à chercher une vérité unique, mais à révéler des dynamiques, à clarifier des zones d’incertitude et à rendre visibles des comportements qui, jusqu’ici, échappaient à toute lecture systématique. Le modèle que nous avons construit n’est pas une réponse définitive, mais un prisme qui permet de voir plus justement ce qui se joue derrière chaque rejet.
L’une des grandes forces de cette démarche est d’avoir replacé l’humain au centre. En donnant aux équipes un outil interprétable, robuste et aligné sur leur réalité, nous n’avons pas cherché à automatiser la décision, mais à la renforcer. Le score n’est pas un verdict : c’est une indication, un éclairage, un moyen d’investir l’énergie là où elle peut réellement modifier l’issue d’un dossier. C’est cette complémentarité entre l’expertise humaine et la lecture analytique qui donne tout son sens au projet.
Nous avons également découvert que la valeur d’un modèle ne réside pas uniquement dans sa capacité à prédire, mais dans sa capacité à faire évoluer nos pratiques. En structurant notre compréhension autour de trajectoires plutôt que d’incidents isolés, nous avons fait évoluer notre manière d’accompagner les clients, notre manière de prioriser nos actions, et plus largement notre manière de penser la gestion des impayés. Cette évolution n’est pas un effet secondaire : elle est au cœur de l’ambition du projet.
Enfin, nous savons que ce modèle n’est qu’une étape. Les comportements évolueront, les flux changeront, les systèmes progresseront. Le modèle devra être réévalué, ajusté, enrichi. Sa pertinence dépendra de notre capacité à rester attentifs aux signaux faibles, aux dérives, aux transformations du contexte bancaire et assurantiel. C’est précisément cette dynamique continue qui fait de ce projet un terrain d’apprentissage permanent.
En rendant intelligibles des comportements longtemps perçus comme imprévisibles, nous avons créé un outil durable qui permet de mieux comprendre, mieux anticiper et mieux agir. Et si cette première version n’est qu’un socle, elle est déjà une avancée majeure : elle marque le moment où nous avons commencé à lire les impayés non plus comme des obstacles, mais comme des informations, des trajectoires, des histoires que nous pouvons enfin interpréter et accompagner avec justesse.